Concurrent Theta sketch is a manifestation of a generic approach for parallelizing sketches while bounding the error such parallelism introduces1.
At its core, a generic concurrent sketch ingests data through multiple sketches that are local to the inserting threads.
The data in these local sketches, which are bounded in size, is merged into a single shared sketch by utilizing the sketch mergability property.
Queries are served from a snapshot of the shared sketch.
This snapshot is taken frequently enough to guarantee the result’s freshness, and seldom enough to not become the bottleneck of the sketch.
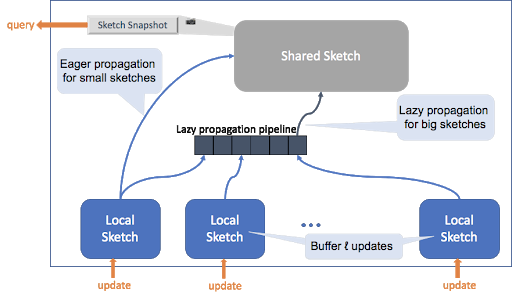
Unlike previous solutions, this design enables simultaneous queries and updates to a sketch from an arbitrary number of threads. The responsibility for merging the thread-local sketch into the shared sketch is divided into two
Both the local sketch and the shared sketch are descendants of UpdateSketch and therefore support its API. However, it is important that the shared sketch is only used to get the estimate, while updates only go through the local sketches. The shared sketch can be allocated either off-heap or on-heap, while the local sketch is always allocated on-heap.
Like other Theta sketches, UpdateSketchBuilder is used to build the shared and local sketches.
It is imperative that the shared sketch is built first.
Then, at the context of an application thread(/s) that feeds the data a local sketch is created and connected to the shared sketch.
This is a list of the configuration parameters for the builder:
import org.apache.datasketches.memory.WritableDirectHandle;
import org.apache.datasketches.memory.WritableMemory;
import org.apache.datasketches.theta.Sketch;
import org.apache.datasketches.theta.UpdateSketch;
import org.apache.datasketches.theta.UpdateSketchBuilder;
class ApplicationWithsketches {
private UpdateSketchBuilder bldr;
private UpdateSketch sharedSketch;
private Thread writer;
private int sharedLgK;
private int localLgK;
private boolean ordered;
private boolean offHeap;
private int poolThreads;
private double maxConcurrencyError;
private int maxNumWriterThreads;
private WritableDirectHandle wdh;
private WritableMemory wmem;
//configures builder for both local and shared
void buildConcSketch() {
bldr = new UpdateSketchBuilder();
// All configuration parameters are optional
bldr.setLogNominalEntries(sharedLgK); // default 12 (K=4096)
bldr.setLocalLogNominalEntries(localLgK); // default 4 (B=16)
bldr.setNumPoolThreads(poolThreads); // default 3
bldr.setPropagateOrderedCompact(ordered); // default true
bldr.setMaxConcurrencyError(maxConcurrencyError); // default 0
bldr.setMaxNumLocalThreads(maxNumWriterThreads); // default 1
// build shared sketch first
final int maxSharedUpdateBytes = Sketch.getMaxUpdateSketchBytes(1 << sharedLgK);
if (offHeap) {
wdh = WritableMemory.allocateDirect(maxSharedUpdateBytes);
wmem = wdh.get();
} else {
wmem = null; //WritableMemory.allocate(maxSharedUpdateBytes);
}
sharedSketch = bldr.buildShared(wmem);
}
void mainApplicationMethod() {
// init attributes, e.g, with properties file
...
buildConcSketch();
writer = new WriterThread(bldr, sharedSketch);
while(#some_application_condition) {
// get estimate through shared sketch
doSomethingWithEstimate(sharedSketch.getEstimate());
try {
Thread.sleep(100);
} catch (final InterruptedException e) {
e.printStackTrace();
}
}
}
}
// Context of writer thread
class WriterThread extends Thread {
private UpdateSketch local;
// build local sketches from bldr and reference to shared sketch
public WriterThread(final UpdateSketchBuilder bldr, final UpdateSketch shared) {
local = bldr.buildLocal(shared);
//init input stream, such as a queue, or a communication buffer, etc.
}
// updtae concurrent sketch through local sketch - no need for locks or any other synchronization
public void run() {
while(true) {
if(#input_stream_is_not_empty) {
long data = getDataFromInputStream();
local.update(data);
}
}
}
A concurrent sketch is not a single unit of computation. It is composed of the shared sketch and the local buffers.
Only the shared sketch supports serialization as it captures the most up-to-date content of the sketch.
In the current implementation, deserializing a shred sketch yields an UpdateSketch.
Therefore when de-serializing a concurrent sketch both the shared sketch and the local buffers need to be re-created again.
import org.apache.datasketches.memory.WritableMemory;
import org.apache.datasketches.theta.Sketch;
import org.apache.datasketches.theta.UpdateSketch;
import org.apache.datasketches.theta.UpdateSketchBuilder;
public class serDeTest {
private UpdateSketchBuilder bldr;
private UpdateSketch sharedSketch;
private WritableMemory wmem;
void serDeConcurrentQuickSelectSketch() {
int k = 512;
// build shared sketch and local buffer as in the example above
bldr = new UpdateSketchBuilder();
...
sharedSketch = bldr.buildShared(wmem);
UpdateSketch local = bldr.buildLocal(sharedSketch);
int i=0;
// update sketch through local buffer
for (; i<10000; i++) {
local.update(i);
}
// serialize shared
byte[] serArr = shared.toByteArray();
Memory srcMem = Memory.wrap(serArr);
Sketch recovered = Sketches.heapifyUpdateSketch(srcMem);
//reconstruct to Native/Direct
final int bytes = Sketch.getMaxUpdateSketchBytes(k);
wmem = WritableMemory.allocate(bytes);
shared = bldr.buildSharedFromSketch((UpdateSketch)recovered, wmem);
UpdateSketch local2 = bldr.buildLocal(shared);
// check estimate ~10K
System.out.println("Estimate="+sharedSketch.getEstimate();
// continue updating through new local buffer
for (; i<20000; i++) {
local2.update(i);
}
// check estimate ~20K
System.out.println("Estimate2="+sharedSketch.getEstimate();
}
}
[1] Arik Rinberg, Alexander Spiegelman, Edward Bortnikov, Eshcar Hillel, Idit Keidar, Hadar Serviansky, Fast Concurrent Data Sketches, https://arxiv.org/abs/1902.10995

