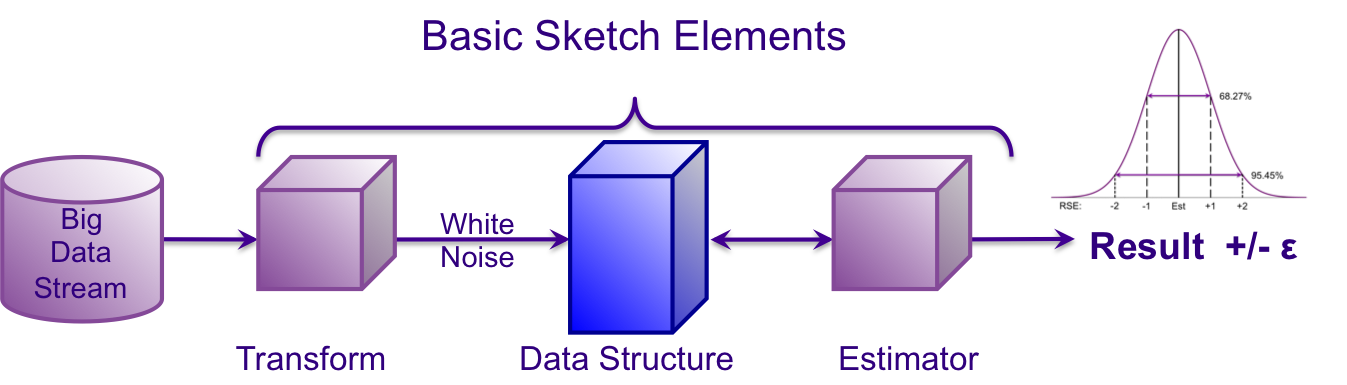
Sketches are different from traditional sampling techniques in that sketches examine all the elements of a stream, touching each element only once, and often have some form of randomization that forms the basis of their stochastic nature. This “one-touch” property makes sketches ideally suited for real-time stream processing.
As an example, the first stage of a count-distinct sketching process is a transformation that gives the input data stream the property of white noise, or equivalently, a uniform distribution of values. This is commonly achieved by coordinated hashing of the input unique keys and then normalizing the result to be a uniform random number between zero and one.
The second stage of the sketch is a data structure that follows a set of rules for retaining a small set of the hash values it receives from the transform stage. Sketches also differ from simple sampling schemes in that the size of the sketch often has a configurable, fixed upper bound, which enables straightforward memory management.
The final element of the sketch process is a set of estimator algorithms that upon a request examine the sketch data structure and return a result value. This result value will be approximate but will have well established and mathematically proven error distribution bounds.
Sketches are typically1
1 For a more comprehensive definition see Sketch Criteria

