This is an algorithm and data structure for estimating ranks and quantiles of distributions of numerical values.
The implementation in this library is based on the MergingDigest in following reference implementation.
The implementation in this library has a few differences from the reference implementation:
Unlike all other algorithms in the library, t-digest is empirical and has no mathematical basis for estimating its error and its results are dependent on the input data. However, for many common data distributions, it can produce excellent results.
The library contains a few different quantile sketches for estimating distributions (ranks and quantiles). All other quantile skeches can handle arbitrary comparable types and always retain a small set of items from the input stream. All queries that return approximations in the input domain return one of the retained items from the input. t-digest is different: it works on numeric data only (floating point types), retains and returns values not necessarilly seen in the input (interpolated).
The closest alternative to t-digest in this library is REQ sketch. It prioritizes one chosen side of the rank domain: either low rank accuracy or high rank accuracy. t-digest (in this implementation) prioritizes both ends of the rank domain and has lower accuracy towards the middle of the rank domain (median).
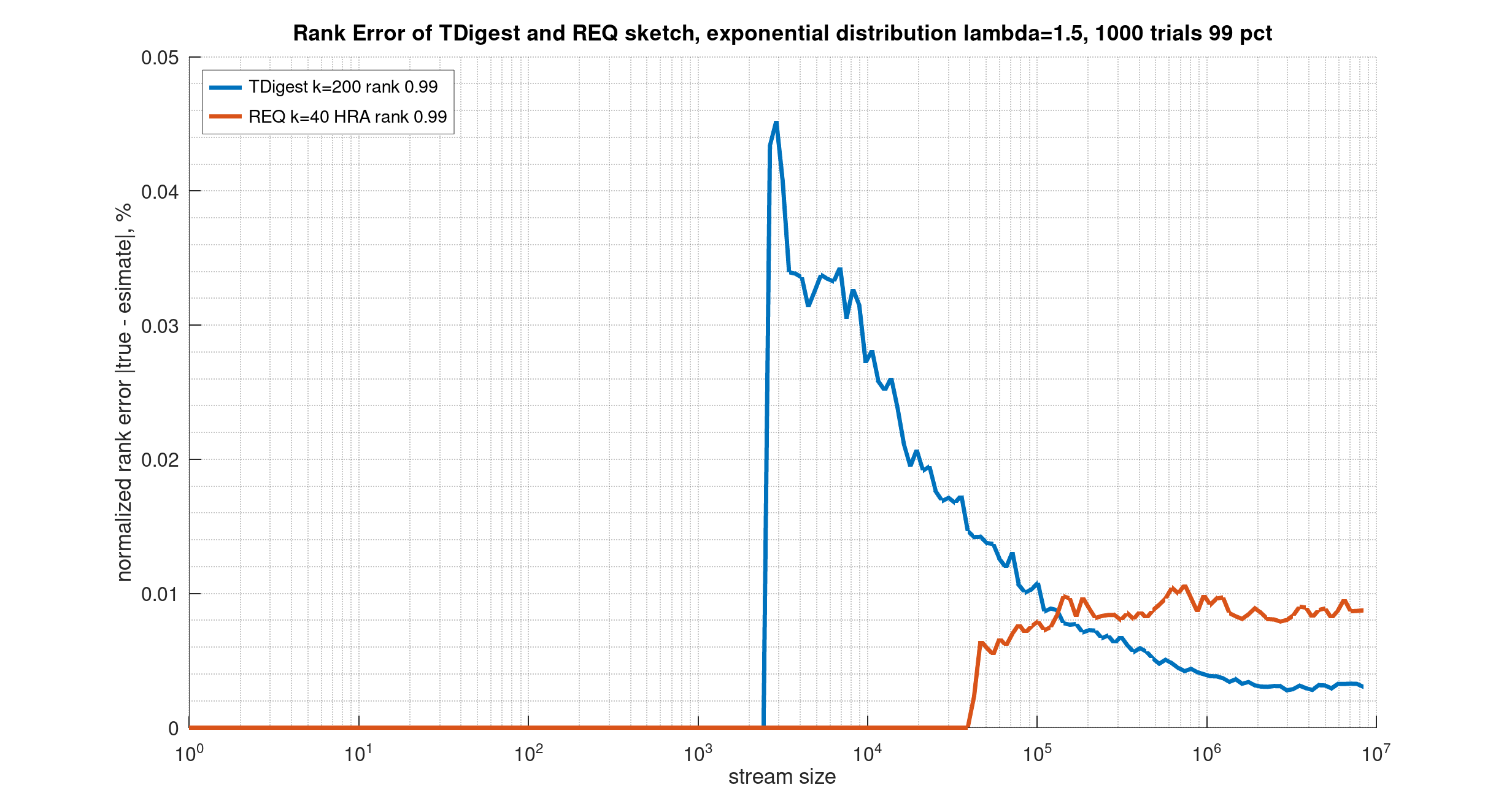
Measurements show that t-digest is slightly biased (tends to underestimate low ranks and overestimate high ranks), while still doing very well close to the extremes. The effect seems to be more pronounced with more input values:
![]()
![]()
![]()
![]()
Rank error vs stream size:
![]()
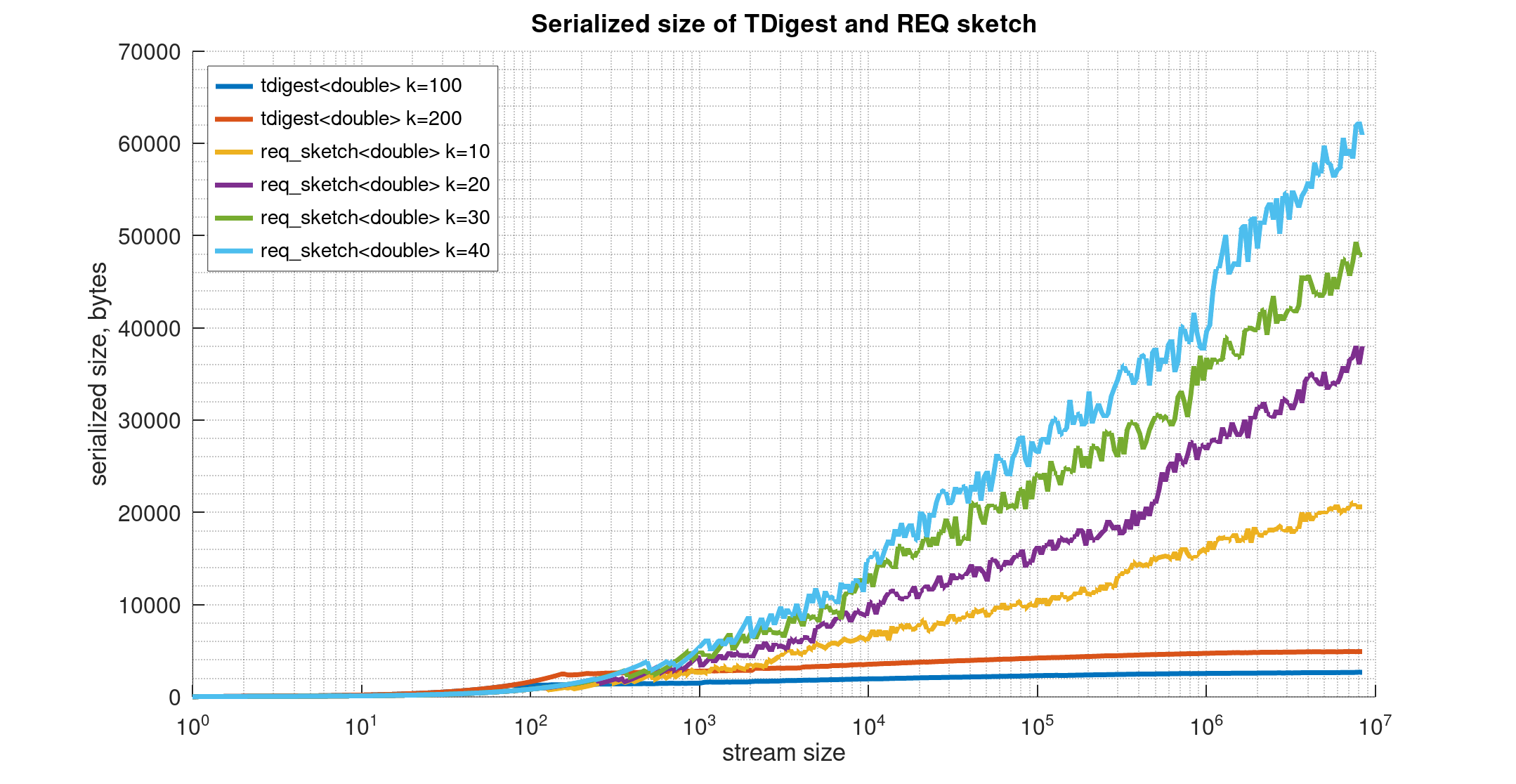
Comparisons with REQ sketch:

![]()