Please see the Sketch Features Matrix for a detailed comparison of the features of the different sketches in the library.
This sketch was developed by the late Keven J. Lang, our chief scientist at the time. It is an amazing tour de force of scientific design and engineering and has substantially better accuracy / per stored size than the famous HLL sketch. The theory and demonstration of its performance is detailed in Lang’s paper Back to the Future: an Even More Nearly Optimal Cardinality Estimation Algorithm.
Internet content, search and media companies like Yahoo, Google, Facebook, etc., collect many tens of billions of event records from the many millions of users to their web sites each day. These events can be classified by many different dimensions, such as the page visited and user location and profile information. Each event also contains some unique identifiers associated with the user, specific device (cell phone, tablet, or computer) and the web browser used.

These same unique identifiers will appear on every page that the user visits. In order to measure the number of unique identifiers on a page or across a number of different pages, it is necessary to discount the identifier duplicates. Obtaining an exact answer to a COUNT DISTINCT query with massive data is a difficult computational challenge. It is even more challenging if it is necessary to compute arbitrary expressions across sets of unique identifiers. For example, if set S is the set of user identifiers visiting the Sports page and set F is the set of user identifiers visiting the Finance page, the intersection expression S ∩ F represents the user identifiers that visited both Sports and Finance.
Computing cardinalities with massive data requires lots of computer resources and time. However, if an approximate answer to these problems is acceptable, Theta Sketches can provide reasonable estimates, in a single pass, orders of magnitude faster, even fast enough for analysis in near-real time.
The theta/Sketch can operate both on-heap and off-heap, has powerful Union, Intersection, AnotB and Jaccard operators, has a high-performance concurrent form for multi-threaded environments, has both immutable compact, and updatable representations, and is quite fast. Because of its flexibility, it is one of the most popular sketches in our library.
It is often not enough to perform stream expressions on sets of unique identifiers, it is very valuable to be able to associate additive data with these identifiers, such as impression counts, clicks or timestamps. Tuple Sketches are a natural extension of the Theta sketch and have Java Genric forms that enable the user to define the sketch with arbitrary “summary” data. The tuple/Sketch can operate both on-heap and off-heap, includes both Union and Intersection operators, and has both immutable compact and updatable representations.
The Tuple sketch is effectively infinitely extendable and there are several common variants of the Tuple Sketch, which also serve as examples on how to extend the base classes that are also in the library, including:
The HyperLogLog (HLL) is a cardinality sketch similar to the above Theta sketches except they are anywhere from 2 to 16 times smaller in size. The HLL sketches can be merged via the Union operator, but set intersection and difference operations are not provided intrinsically, because the resulting error would be quite poor. If your application only requires cardinality estimation and merging and space is at a premium, the HLL or CPC sketches would be your best choice.
The hll/HllSketch can operate both on-heap and off-heap, provides the Union operators, and has both immutable compact and updatable representations.
This is a specially designed sketch that addresses the problem of individually tracking value cardinalities of Key-Value (K,V) pairs in real-time, where the number of keys can be very large, such as IP addresses, or Geo identifiers, etc. Assigning individual sketches to each key would create unnecessary overhead. This sketch streamlines the process with much better space management. This hllmap/UniqueCountMap only operates on heap and does not provide Union capabilites. This sketch is effectively a optimized hash-map of HLL sketches. Like other hash-maps, the overall size is a direct function of the number of keys that it has seen. This sketch was designed to operate as a stand-alone sketch.
There are many situations where is valuable to understand the distribution of values in a stream. For example, from a stream of web-page time-spent values, it would be useful to know arbitrary quantiles of the distribution, such as the 25th percentile value, the median value and the 75th percentile value. The Quantiles Sketches solve this problem and enable the inverse functions such as the Probability Mass Function (PMF) and the Cumulative Distribution Function (CDF) as well. It is relatively easy to produce frequency histograms such as the following diagram, which was produced from a stream of over 230 million time spent events. The space consumed by the sketch was about 43KB.
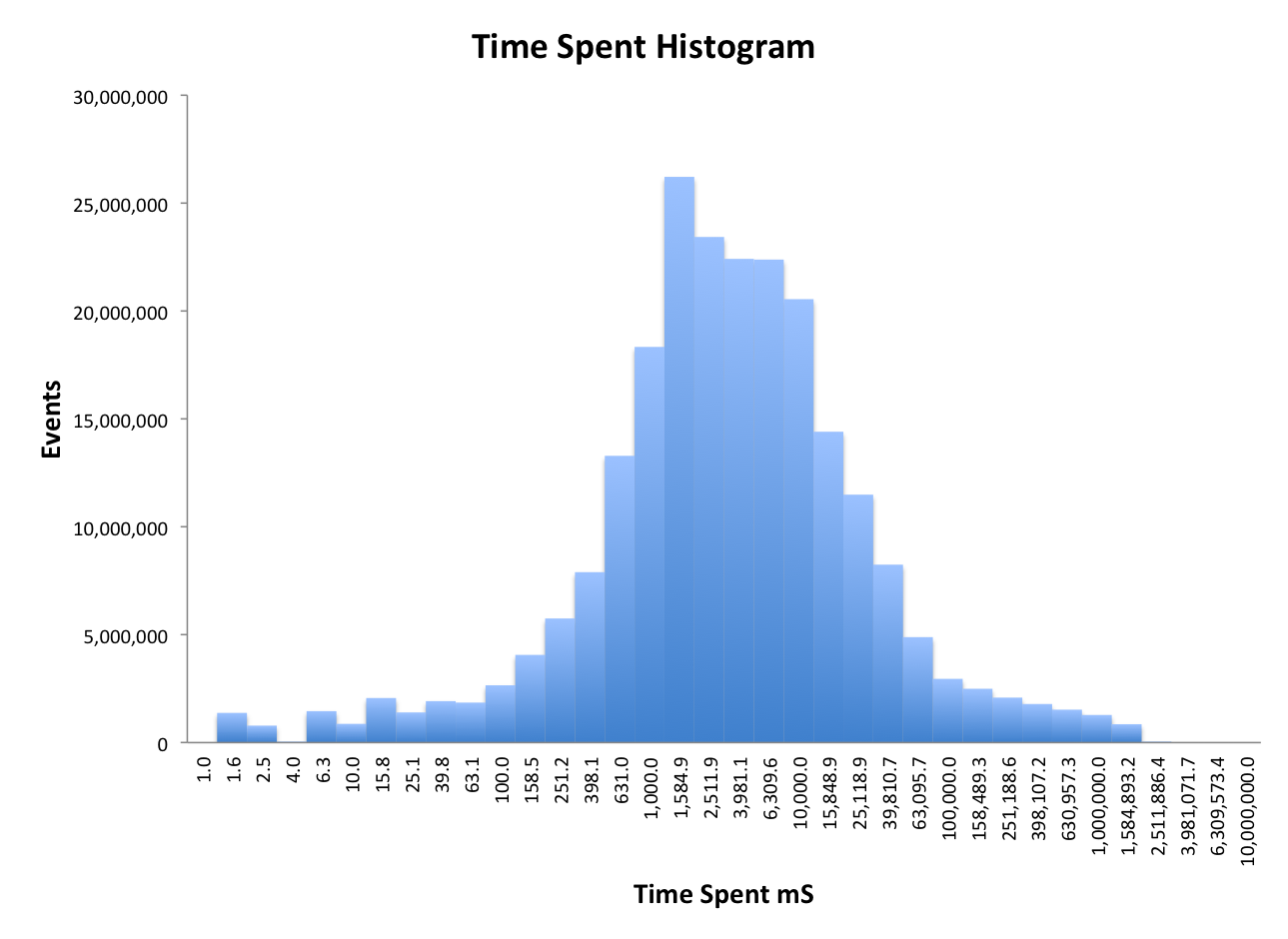
There are two different families of quantiles sketches, the original quantiles/DoublesSketch, which can be operated either on-heap or off-heap, and is also available in a Java Generic form for arbitrary comparable objects.
Later we developed the kll/KllSketch (Named after its authors), which is also a quantiles sketch, that achieves near optimal small size for a given accuracy.
The most recent sketch in this group is called the Relative Error Quantiles ReqSketch, which is a cousin of the KLL sketch except that it provides very high accuracy at one of the ends of the rank domain. If your application requires high accuracy primarily for the very high ranks, e.g., the 99.999%ile, or the very low ranks, e.g. the .00001%ile, and you can give up some accuracy at the other end of the rank scale, this sketch is designed for you.
It is very useful to be able to scan a stream of objects, such as song titles, and be able to quickly identify those titles that occur most frequently. The term Heavy Hitter is defined to be an item that occurs more frequently than its fair share of occurrences. This “fair share” is simply the total count of all occurrences of all items divided by the number of distinct items. Suppose you have a stream of 1M song titles, but in that stream there are only 100K song titles that are unique. If any single title consumes more than 10% of the stream elements it is a Heavy Hitter. The 10% is a threshold parameter we call epsilon.
The accuracy of a Frequent Items Sketch is proportional to the configured size of the sketch, the larger the sketch, the smaller is the epsilon threshold that can detect Heavy Hitters. This sketch is available in two forms, as the frequencies/LongsSketch used for processing a stream of tuples {long, weight}, and the frequencies/ItemsSketch used for processing tuples of {T, weight}, where T is arbitrary, uniquely identifyable object. These sketches are aggregating sketches in that the frequency of occurances of an item (or long key), is accumulated as the stream is processed.
Suppose our data is a stream of pairs {IP address, User ID} and we want to identify the IP addresses that have the most distinct User IDs. Or conversely, we would like to identify the User IDs that have the most distinct IP addresses. This is a common challenge in the analysis of big data and the FDT sketch helps solve this problem using probabilistic techniques.
More generally, given a multiset of tuples with N dimensions {d1,d2, d3, …, dN}, and a primary subset of dimensions M < N, our task is to identify the combinations of M subset dimensions that have the most frequent number of distinct combinations of the N - M non-primary dimensions.
The fdt/FdtSketch is currently only available in Java, but because it is an extension of the Tuple Sketch family, it inherits many of the same properties: it can operate both on-heap and off-heap, it includes both Union and Intersection operators, and it has both immutable compact and updatable representations.
Part of a new separate datasketches-vector component, Frequent Directions is in many ways a generalization of the Frequent Items sketch in order to handle vector data. This sketch computes an approximate singular value decomposition (SVD) of a matrix, providing a projection matrix that can be used for dimensionality reduction. SVD is a key technique in many recommender systems, such as providing shopping suggestions based on a customer’s past purchases compared with other similar customers. This sketch is still experimental and feedback from interested users would be welcome. This sketch can be found in the Vector repository dedicated to vector and matrix sketches.
This family of sketches implements an enhanced version of the famous Reservoir sampling algorithm and extends it with the capabilities that large-scale distributed systems really need: mergability (even with different sized sketches). The Java implementaion uses Java Generics so that the base classes can be trivially extended for any input type (even polymorphic types), and also enables an extensible means of performing serialization and deserialization.
The sampling/ReservoirLongsSketch accepts a stream of long values as identifiers with a weight of one, and produces a result Reservoir of a pre-determined size that represents a uniform random sample of the stream.
The sampling/ReservoirItemsSketch accepts a stream of type T as identifiers with a weight of one, and produces a result Reservoir of a pre-determined size that represents a uniform random sample of the stream.
This family of sketches implements an enhanced version of Edith Cohen, et al, “Stream sampling for variance-optimal estimation of subset sums” and extends it with the capabilities that large-scale distributed systems really need: mergability (even with different sized sketches). The Java implementaion uses Java Generics so that the base classes can be trivially extended for any input type (even polymorphic types), and also enables an extensible means of performing serialization and deserialization.
The sampling/VarOptItemsSketch extends the Reservoir family to weighted sampling, additionally providing subset sum estimates from the sample with provably optimal variance.

